

The Agentic Engineering Shift
Karpathy named two extremes. Here is the spectrum that covers everything in between, and the habits that shift you in the right direction.

The fastest way to build a product you cannot maintain is to let AI write all of it without asking questions.
Sure, you will ship faster than anyone in the room. Yeah, the demo will work. But two weeks later, when a user reports a bug, you will open the file and scroll through functions you do not remember writing. Because you did not write them. The AI did. You accepted the output, tested the happy path, and moved on.
Changing one line feels dangerous because you cannot trace what it touches. The code works, but you do not own it. You are maintaining a stranger’s project inside your own repo.

Andrej Karpathy gave this gap a name. In February 2025 he coined “vibe coding” to describe the practice of accepting AI output without scrutiny. A year later he followed up with “agentic engineering,” the practice of orchestrating AI agents with oversight, structure, and human judgment at every step.
The naming matters because thousands of builders recognized themselves in it. But a label does not tell you what to change. This post gives you a way to figure out where you sit on the spectrum between the two and which practices will move you forward.
If you have read How To Architect A Feature In 5 Minutes Before Talking To AI, you already know why thinking before prompting matters. This piece picks up where that one left off. Thinking before prompting is the starting habit. What follows is the full set of habits that separates builders who ship from builders who ship and survive.
In this edition:
What Karpathy’s two terms mean and where the conversation stops being useful
A 4-stage maturity spectrum to locate where you are right now
The 5 workflow practices that make the shift from vibe coding to agentic engineering concrete
A 60-second diagnostic you can run on your last shipped feature tonight


What Karpathy Named
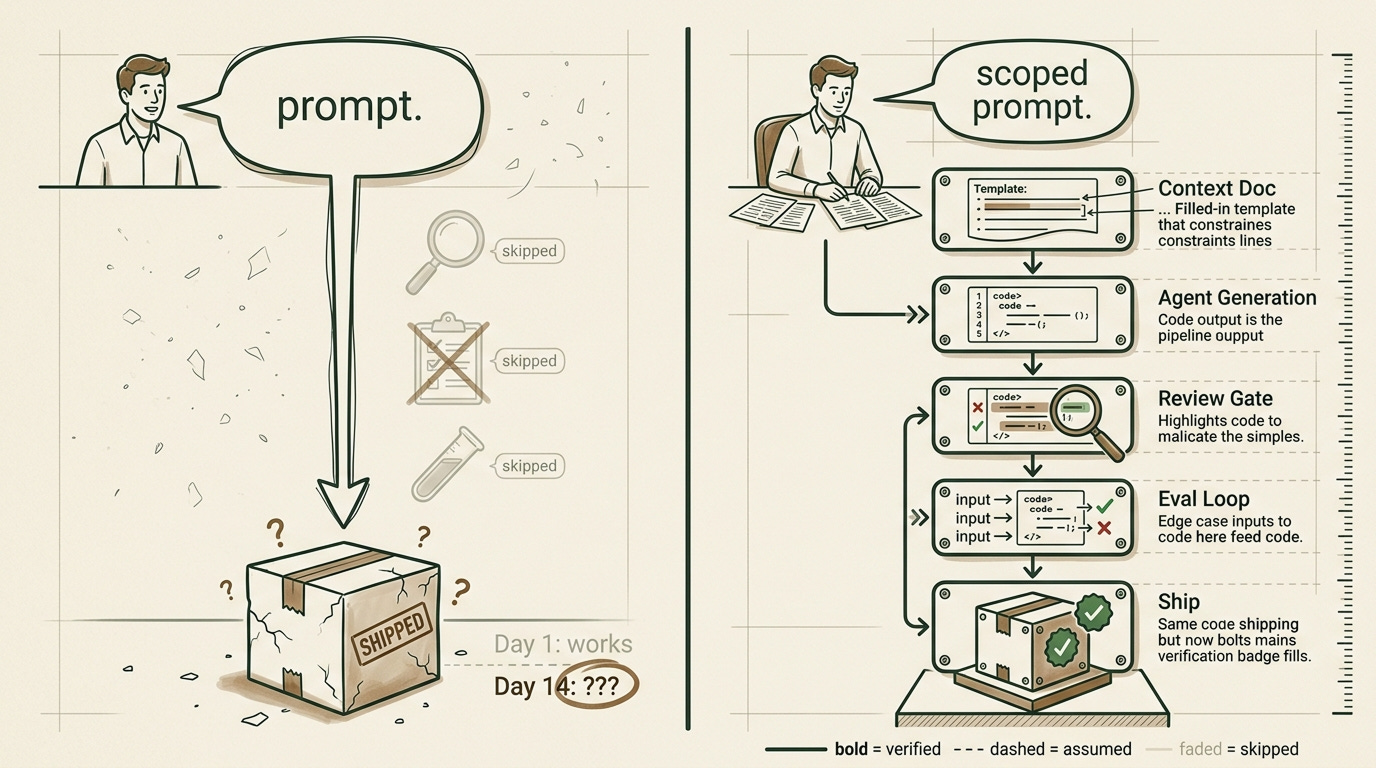
Vibe coding means giving an AI a prompt, getting code back, and shipping it without meaningful review. You trust the output because it runs. You move fast because the feedback loop feels instant.
The AI writes a function, you glance at the result, and if nothing throws an error, it goes into the codebase.
Agentic engineering means working with AI agents as part of a structured process. You provide context, define constraints, review outputs, run evaluations, and make the final call on what ships.
The AI still does the heavy lifting, but YOU direct the work and own the result. Every piece of generated code passes through your judgment before it touches production. And this goes beyond coding.
Both terms describe real behaviors that builders already practiced before the vocabulary existed. Karpathy gave the community a shared language for something people felt but struggled to articulate. The developer copying AI output straight into a feature branch at 2am was vibe coding long before anyone named it.
The problem is that most of the conversation stopped at the labels. Forums and comment sections turned it into a binary: vibe coding bad, agentic engineering good. That framing misses the point.
Nobody operates at one extreme all the time. A solo builder prototyping on a Saturday afternoon and a team shipping a payments feature to 10,000 users should not follow the same process. The real question is what specific behaviors separate one from the other, and how you move between them.
The Spectrum
This is not a pass/fail test. Builders sit at different points on a gradient, and the position shifts depending on the project, the deadline, and the stakes. The useful exercise is recognizing where you are right now based on what you do, not what you believe.
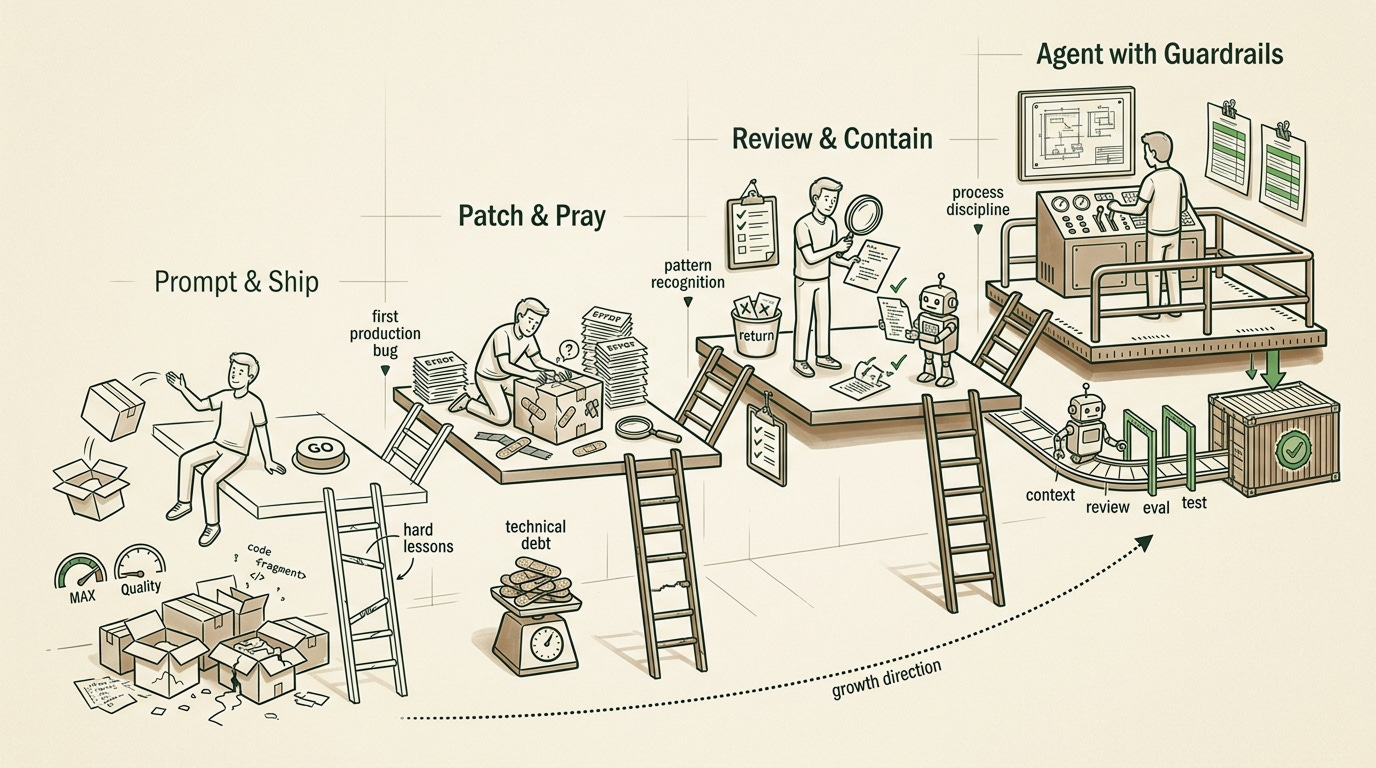
Stage 1: Prompt and Ship
You describe what you want. The AI writes it. If the output runs, you merge it. Testing means clicking through the feature once to confirm it loads.
This works for throwaway prototypes and weekend experiments. The failure mode shows up later. Features become untouchable because you cannot predict what changing one piece will break.
You open a file, see 200 lines of logic, and realize you have no idea why the AI structured it that way. Every revisit feels like defusing a bomb you did not build.
Stage 2: Patch and Pray
Bugs appear. You fix them by prompting the AI again with the error message. The fix works, but you still do not understand the underlying structure. You know fragments of the codebase. You do not know the system.
This is where most builders I see in forums and Reddit threads are sitting right now. The product shipped. Users showed up. And every maintenance task takes three times longer than it should because the codebase grew in directions nobody planned.
The failure mode here is compounding. Each reactive patch adds weight. You fix the form validation bug and break the error toast. You fix the error toast and notice the loading state flickers. Confidence drops with every fix because you are never sure the patch did not break something else. The codebase starts to feel adversarial.
Stage 3: Review and Contain
You start reading the AI’s output before merging. You notice recurring patterns in what the AI gets wrong. You add checks. You push back on suggestions that feel over-engineered or unclear.
At this stage, AI becomes a fast junior developer on your team rather than an oracle. You treat its output the way a senior developer treats a pull request from someone in their first year. You catch the unnecessary abstraction. You question why it created three helper functions when one would do.
The failure mode is inconsistency. The review habit exists, but it drops off when you are tired, rushed, or excited about a feature. Friday afternoon, deadline looming, a new feature working on the first try. The temptation to merge without reviewing is strongest when the output looks clean. Process without discipline reverts to vibe coding under pressure.
Stage 4: Agent with Guardrails
You work with explicit context documents, evaluation criteria, test expectations, and review gates. You can explain why every function exists and what conditions would break it. The AI still generates the code. You architect the system and verify the output.
The failure mode even here is over-automation. Trusting the process so fully that you stop applying judgment to edge cases. The test suite passes, the evaluation loop looks green, and you ship without reading the diff. Process is a tool, not a replacement for thinking.
Most builders reading this will recognize themselves somewhere in stages 2 or 3. That recognition is the starting point. The next section covers what moves you forward.
If you have been through The Build vs Buy Scorecard, you already know the value of slowing down before making technical decisions. The same principle applies here. The spectrum rewards deliberate behavior over fast output.


The Practices
The shift from vibe coding to agentic engineering is visible in workflow, not philosophy. These are five habits you can observe yourself doing, or not doing. Each one addresses a specific failure mode from the spectrum above.
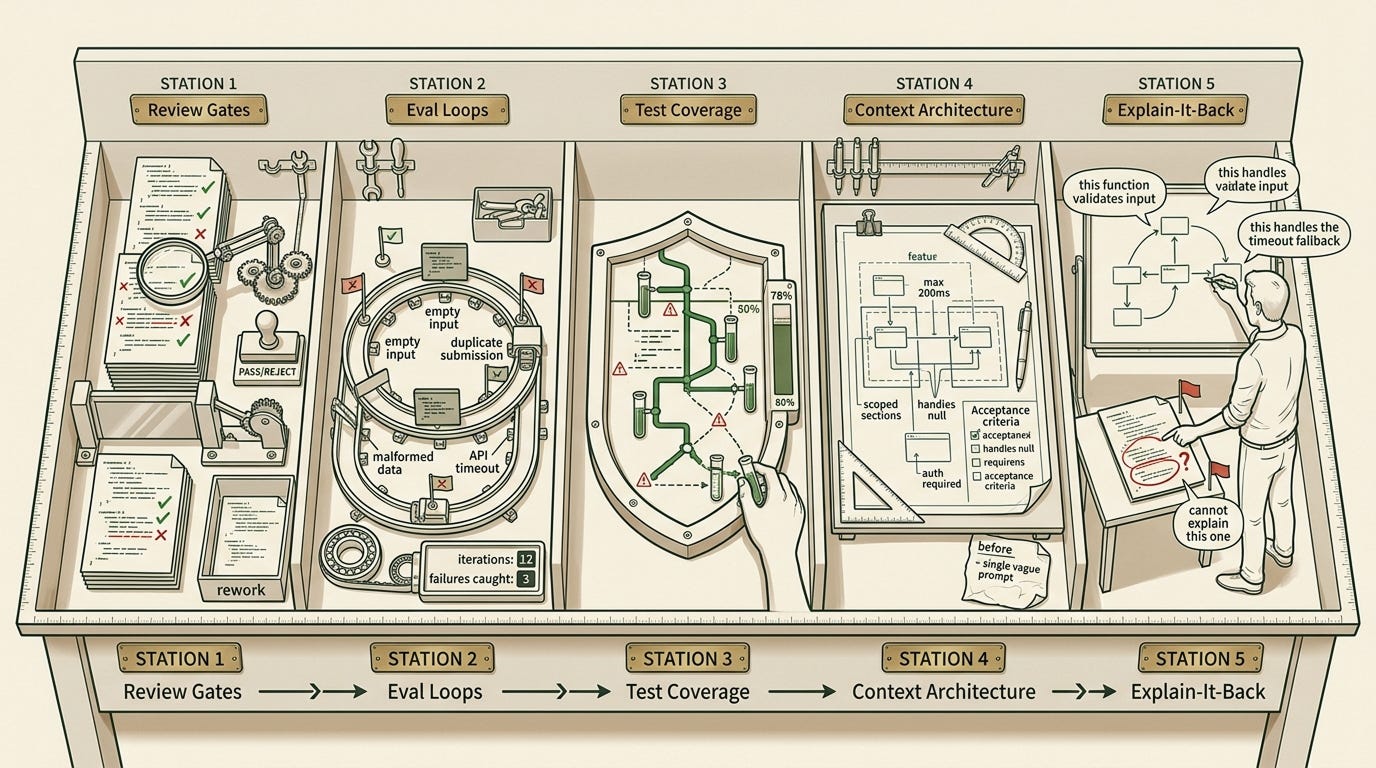
1. Review Gates
Treat every AI output like a pull request from a junior developer. Read the code before you merge it. Check whether the approach matches what you asked for. Look for unnecessary complexity, redundant calls, or logic you cannot follow.
When you skip this: you inherit code you cannot reason about. The AI might add a caching layer you never asked for, or restructure your data flow in a way that makes sense in isolation but clashes with the rest of your system. The codebase grows in ways you did not choose, and every future change requires re-learning what the AI decided on your behalf.
2. Eval Loops
Test more than “does it work once.” Feed the AI’s code edge cases, unexpected inputs, and failure scenarios. If you built a form handler, send it empty fields, duplicate submissions, and malformed data. Check what happens when the external API is slow or down.
When you skip this: the AI passes the demo and fails the real world. You find the bugs in production instead of in development, and your users find them before you do.
3. Test Coverage for Agent Output
If the agent wrote the code, someone needs to verify it holds up. Write tests for the critical paths. If you do not write tests yourself, at minimum run the feature through its failure modes manually before shipping.
When you skip this: “works in dev” becomes “breaks in production.” Maintenance turns into archaeology because you are digging through code with no map of what was supposed to happen. You can pair this with the approach in How to Prompt AI for Consistent JSON Responses to make sure the outputs you are testing against stay predictable.
4. Context Architecture
The quality of AI output depends on the quality of your input. Before prompting, define what the feature needs to handle, what it connects to, and what constraints exist. Break the problem into scoped pieces. Give the agent acceptance criteria, not open-ended requests.
When you skip this: the agent guesses the system you meant. It fills in gaps with assumptions pulled from training data, and those assumptions may not match your product, your users, or your stack. You ask for a notification system and get a full pub/sub architecture when all you needed was a database flag and a polling endpoint. This is where the 5-minute architecture sketch pays off the most.
5. The Explain-It-Back Check
Before shipping any AI-generated code, explain what it does in your own words. Walk through the logic, the data flow, and the failure path. If you hit a function you cannot explain, that is the part that will break first in production.
When you skip this: ownership never transfers back to you. The code ships under your name, but the understanding stays with the model that generated it. When a user reports a bug at 11pm, you will stare at the function and have no starting point for debugging it. You become a passenger in your own project.
None of these practices make AI infallible. AI will still produce flawed output, miss edge cases, and make assumptions you did not ask for. These practices make your relationship to that output honest. You stop hoping the code is correct and start knowing where to look when it is not. The AI handles generation. You handle judgment. That division of labor is the entire point.

Tell me which practice from this list you have started doing, or which one you know you have been skipping. Drop it in the comments.

The 60-Second Test
Open the last feature you shipped with AI assistance. Pick any file from that feature and read through it.
For each function, check three things. Whether you can explain what it does without reading it line by line. Whether you know what happens when it fails. Whether there is a test covering the critical path.
If you breeze through all three, pick a second file. Keep going until you hit the wall. Most builders find it faster than they expect.
The first question you cannot answer marks your starting point on the spectrum. That is the exact spot where your next upgrade begins. You do not need to fix everything at once. Pick one practice from the list above that addresses the failure mode you are sitting in, and apply it to the next feature you build.

Related Articles



